Open innovation involves a high degree of trust and belief among collaborating partners (Lam et al. 2021; Ogink et al. 2023). This notion suggests that companies benefit from the knowledge and capabilities of a wide array of stakeholders, including of their human resources, as well of external participants (Lippolis et al. 2023; Luan and Wang 2024). Practitioners may avail themselves of expert individuals and organizations who are not members of staff in their organization. Hence, they could collaborate with other businesses, enterprises, and startups as well as with institutions like universities to achieve their organizations’ objectives (Cappellaro et al. 2019). Various commentators noted that stakeholder engagement could lead to win-win outcomes for all parties involved in open innovation partnerships (Camilleri et al. 2023; Diriker et al. 2023; Kim et al. 2024). Very often, they confirmed that when practitioners worked in tandem with external stakeholders’ practitioners, they were in a better position to improve their operational performance, in terms of incremental and radical innovations, as opposed to when they were on their own (Radicic and Alkaraan 2024).
Several researchers indicated that businesses could increase their competitive advantage and enhance their research and development (R&D) capabilities when they forge collaborative agreements with consultants, disruptive startups, agile companies, reliable suppliers, and excellent universities with cutting-edge facilities as well as with their talented researchers (Beck et al. 2023; Chen 2018). This is in stark contrast with secretive, closed-innovation mentalities characterized when organizations withhold knowledge and ideas generated by their own intellectual capital and internal resources (Barbic et al. 2021; Yoshino et al. 2023). In this case, firms are very careful not to leak insider information to external stakeholders.
Elements of open innovation
Generally, open innovation ecosystems comprise (i) intellectual property management (Ahlfänger et al. 2022; Fu et al. 2022; Greco et al. 2022; Grimaldi et al. 2021; Jesus et al. 2024; Naveed et al. 2020; Oke 2023), (ii) open innovation culture and governance (Avnimelech and Amit 2024; Lippolis et al. 2023), (iii) inbound innovation (outside-in innovation) (Barjak and Heimsch 2023; Cappellaro et al. 2019; Pilav-Velic and Jahic 2022), (iv) outbound innovation (inside-out innovation) (de Andrés-Sánchez et al. 2022; Remneland Wikhamn and Styhre 2019), (v) coupled innovation (cocreation) (Cammarano et al. 2022), (vi) open innovation intermediaries (Caloffi et al. 2023), and (vii) corporate innovation hubs (Amann et al. 2022; Corvello et al. 2023). Practitioners may avail themselves of open innovation systems to access diverse ideas, resources, and capabilities from their own human resources’ talent pool, and more importantly, from knowledgeable external sources. Table 1 sheds light on the most popular open innovation concepts and provides their definitions.
(Source: Camilleri, 2025)
Suggested citation: Camilleri, M. A. (2025). Cocreating value through open circular innovation strategies: a results‐driven work plan and future research avenues. Business Strategy and the Environment, 34(4), 4561-4580.
Artificial intelligence (AI) and automation technologies are transforming service industries, including finance, healthcare, hospitality, retail, education, public services and digital platforms. While algorithmic decision-making systems, service robots, chatbots, predictive analytics and automated workflows offer enhanced efficiencies, personalization possibilities and scalability potential, these technologies are also raising profound ethical concerns related to their modus operandi and explainability of their outputs (Camilleri, 2024; Hu & Min, 2023).
As AI-driven service systems increasingly mediate interactions between organisations and their stakeholders; ethical failures and bias have the potential to reinforce existing social inequalities, undermine their trustworthiness, service quality, organisational legitimacy and broader societal well-being (Camilleri et al., 2024). Moreover, opaque “black-box” models reduce transparency and could erode user trust in these machine learning technologies (Kordzadeh & Ghasemaghaei, 2022). Unclear accountability structures may obscure responsibility for service failures or might facilitate unintended harmful outcomes (Novelli et al., 2024). These challenges are particularly evidenced in service contexts where human–AI interactions are frequent, relational and consequential.
Such concerns are clearly illustrated in healthcare services (Procter et al., 2023), where AI-driven diagnostic and triage systems are increasingly used to support clinical decision-making. When these technologies rely on biased or unrepresentative training data, they may systematically underdiagnose or misclassify specific demographic groups. Given the high-stakes and the relational nature of healthcare encounters, limited transparency and explainability can significantly diminish patient trust while raising serious ethical and accountability concerns.
Similar issues arise in financial and insurance services (Oke & Cavus, 2025), where automated credit scoring, loan approval and underwriting systems directly influence individuals’ financial inclusion and long-term economic prospects. Algorithmic opacity makes it difficult for customers to understand, question or contest adverse decisions. Therefore, biased models may perpetuate or amplify socioeconomic inequalities. Such an outcome is particularly problematic in service relationships characterised by long-term dependency and trust.
Ethical challenges are also conspicuous in customer service and frontline interactions (Han et al., 2023), where chatbots and virtual assistants handle large volumes of customer inquiries across retail, telecommunications and travel services (Lv et al., 2022). Although these systems offer efficiency and scalability benefits, there are instances where they fail to recognise emotional distress, cultural differences, or exceptional circumstances. Excessive automation can therefore undermine relational service quality, especially when customers are unable to escalate complex or sensitive issues to human agents (Yang et al., 2022).
In public service contexts, governments are progressively deploying AI systems (Willems et al., 2023) to allocate welfare benefits, determine assess eligibility and detect fraud. In such settings, automated decisions can have profound implications for the citizens’ livelihoods and their inclusion in cohesive societies Ethical concerns become particularly acute when accountability is diffused between public agencies and technology providers, as well as when affected individuals lack meaningful mechanisms for appeal, explanation or redress.
Likewise, platform-based and gig economy services are increasingly relying on algorithmic management systems to assign tasks, evaluate performance and to compute remunerations (Kadolkar et al., 2025). These systems often operate as “black boxes,” leaving workers uncertain about how ratings, penalties or income calculations are determined. The resulting lack of transparency and of clear accountability structures can weaken trust, exacerbate power asymmetries and could intensify worker vulnerability within ongoing service relationships.
Notwithstanding, more human resource management and recruitment specialists are adopting AI-enabled tools for résumé screening and to assess their candidates’ credentials (Soleimani et al., 2025). Possible bias embedded within these systems may disadvantage certain social groups. Their limited transparency can prevent applicants from understanding how hiring decisions are made. Such practices raise important ethical questions concerning fairness, informed consent and procedural justice within professional service contexts.
This special issue seeks to advance novel insights into the above ethical implications of AI and automation in services industries. The guest editors look forward to receiving original, interdisciplinary contributions that critically examine how ethical principles can be embedded into the design, governance, implementation and evaluation of AI-enabled service systems.
Aims and scope
The special issue aims to:
· Deepen understanding of ethical risks and dilemmas associated with AI and automation in service industries.
· Explore mechanisms for bias detection, mitigation and governance in service algorithms.
· Examine transparency, explainability and accountability in AI-enabled service encounters.
· Advance responsible, human-centered and sustainable approaches to AI-driven service innovation.
Both conceptual, theoretical and empirical contributions are welcome, including qualitative, quantitative, mixed-methods, experimental, design science as well as critical and/or reflexive approaches.
Indicative themes and topics
Submissions may address, but are not limited to, the following topics:
· Algorithmic bias and discrimination in service delivery;
· Ethical design of AI-enabled service systems;
· Transparency and explainability in automated service decisions;
· Accountability and responsibility in human–AI service interactions;
· AI ethics governance, regulation, and standards in service industries;
· Trust, legitimacy and customer perceptions of AI-driven services;
· Ethical implications of service robots and conversational agents;
· Human oversight and hybrid human–AI service models;
· Data privacy, surveillance and consent in digital service platforms;
· Fairness and inclusion in AI-based personalisation and targeting;
· Responsible AI and ESG considerations in service organisations;
· Cross-cultural and institutional perspectives on AI ethics in services;
· Ethical failures, service recovery and crisis communication involving AI;
· Methodological advances for studying ethics in AI-enabled services.
References
Camilleri, M. A., Zhong, L., Rosenbaum, M. S. & Wirtz, J. (2024). Ethical considerations of service organizations in the information age. The Service Industries Journal, 44(9-10), 634-660.
Camilleri, M. A. (2024). Artificial intelligence governance: Ethical considerations and implications for social responsibility. Expert Systems, 41(7), e13406.
Hu, Y., & Min, H. K. (2023). The dark side of artificial intelligence in service: The “watching-eye” effect and privacy concerns. International Journal of Hospitality Management, 110, 103437.
Kadolkar, I., Kepes, S., & Subramony, M. (2025). Algorithmic management in the gig economy: A systematic review and research integration. Journal of Organizational Behavior, 46(7), 1057-1080.
Kordzadeh, N., & Ghasemaghaei, M. (2022). Algorithmic bias: review, synthesis, and future research directions. European Journal of Information Systems, 31(3), 388-409.
Lv, X., Yang, Y., Qin, D., Cao, X., & Xu, H. (2022). Artificial intelligence service recovery: The role of empathic response in hospitality customers’ continuous usage intention. Computers in Human Behavior, 126, 106993.
Novelli, C., Taddeo, M., & Floridi, L. (2024). Accountability in artificial intelligence: What it is and how it works. AI & Society, 39(4), 1871-1882.
Procter, R., Tolmie, P., & Rouncefield, M. (2023). Holding AI to account: challenges for the delivery of trustworthy AI in healthcare. ACM Transactions on Computer-Human Interaction, 30(2), 1-34.
Soleimani, M., Intezari, A., Arrowsmith, J., Pauleen, D. J., & Taskin, N. (2025). Reducing AI bias in recruitment and selection: an integrative grounded approach. The International Journal of Human Resource Management, 1-36.
Willems, J., Schmid, M. J., Vanderelst, D., Vogel, D., & Ebinger, F. (2023). AI-driven public services and the privacy paradox: do citizens really care about their privacy?. Public Management Review, 25(11), 2116-2134.
Yang, Y., Liu, Y., Lv, X., Ai, J., & Li, Y. (2022). Anthropomorphism and customers’ willingness to use artificial intelligence service agents. Journal of Hospitality Marketing & Management, 31(1), 1-23.
Submission Instructions
Submission guidelines
Manuscripts should be prepared according to The Service Industries Journal’s author guidelines and submitted via the journal’s online submission system. During submission, authors should select the special issue title:
“Ethical implications of artificial intelligence (AI) and automation in service industries: Addressing algorithmic bias, opacity and unclear accountability mechanisms”.
All submissions will undergo a double-blind peer review process in accordance with the journal’s standards and policies of Taylor & Francis.
Important dates
Full paper submission deadline: 31st January 2027
First round of reviews: 31st March 2027
Revised manuscript submission: 31st May 2027
Final acceptance: 31st August 2027
Expected publication: 30th November 2027
Contact Information: For informal enquiries regarding the fit of manuscripts or the scope of the special issue, please contact the Leading Guest Editor via Mark.A.Camilleri@um.edu.mt.
This is an excerpt from one of my latest sole-authored articles.
Suggested citation: Camilleri, M.A. (2025). Cocreating Value through Open Circular Innovation Strategies: A Results-Driven Work Plan and Future Research Avenues, Business Strategy and the Environment, https://doi.org/10.1002/bse.4216
This research raises awareness of practitioners’ crowdsourcing initiatives and collaborative approaches, such as sharing ideas and resources with external partners, expert consultants, marketplace stakeholders (like suppliers and customers), university institutions, research centers, and even competitors, as the latter can help them develop innovation labs and to foster industrial symbiosis (Calabrese et al. 2024; Sundar et al. 2023; Triguero et al. 2022). It reported that open innovation networks would enable them to work in tandem with other entities to extend the life of products and their components. It also indicated how and where circular open innovations would facilitate the sharing of unwanted materials and resources that can be reused, repaired, restored, refurbished, or recycled through resource recovery systems and reverse logistics approaches. In addition, it postulates that circular economy practitioners could differentiate their business models by offering product-service systems, sharing economies, and/or leasing models to increase resource efficiencies and to minimize waste.
Arguably, the cocreation of open innovations can contribute to improve the financial performance of practitioners as well as of their partners who are supporting them in fostering closed-loop systems and sharing economy practices. They enable businesses and their stakeholders to minimize externalities like waste and pollution that can ultimately impact the long-term viability of our planet. Figure 1 presents a conceptual framework that clarifies how open innovation cocreation approaches can be utilized to advance circular, closed-loop models while adding value to the businesses’ financial performance.
Figure 1. The intersection of open innovation and the circular economy.
The collaborative efforts between organizations, individuals, and various stakeholders can lead to sustainable innovations, including to the advancement of circular economy models (Jesus and Jugend 2023; Tumuyu et al. 2024). Such practices are not without their own inherent challenges and pitfalls. For example, resource sharing, the recovery of waste and by-products from other organizations, and industrial symbiosis involve close partnership agreements among firms and their collaborators, as they strive in their endeavors to optimize resource use and to minimize waste (Battistella and Pessot 2024; Eisenreich et al. 2021). While the open innovation strategies that are mentioned in this article can lead to significant efficiency gains and to waste reductions, practitioners may encounter several difficulties and hurdles, to implement the required changes (Phonthanukitithaworn et al. 2024). Different entities will have their own organizational culture, strategic goals, and modus operandi that may result in coordination challenges among stakeholders.
Organizations may become overly reliant on sharing resources or on their symbiotic relationships, leading to vulnerabilities related to stakeholder dependencies (Battistella and Pessot 2024). For instance, if one partner experiences disruptions, such as operational issues or financial difficulties, it can adversely affect the feasibility of the entire network. Notwithstanding, organizations are usually expected to share information and resources when they are involved in corporate innovation hubs and clusters. Their openness can lead to concerns about knowledge leakages and intellectual property theft, which may deter companies from fully engaging in resource-sharing initiatives, as they pursue outbound innovation approaches.
Other challenges may arise from resource recovery, reverse logistics, and product-life extension strategies (Johnstone 2024). The implementation of reverse logistics systems can be costly, especially for small and micro enterprises. The costs associated with the collection, sorting, and processing of returned products and components may outweigh the benefits, particularly if the market for recovered materials is not well established (Panza et al. 2022; Sgambaro et al. 2024). Moreover, the effectiveness of resource recovery methodologies and of product-life extension strategies would be highly dependent on the stakeholders’ willingness to return products or to participate in recycling programs. Circular economy practitioners may have to invest in promotional campaigns to educate their stakeholders about sustainable behaviors. There may be instances where existing recovery and recycling technologies are not sufficiently advanced or widely available, in certain contexts, thereby posing significant barriers to the effective implementation of open circular innovations. Notwithstanding, there may be responsible practitioners and sustainability champions that may struggle to find reliable partners with appropriate technological solutions that could help them close the loop of their circular economy.
In some scenarios, emerging circular economy enthusiasts may be eager to shift from traditional product sales models to innovative product-service systems. Yet, such budding practitioners can face operational challenges in their transitions to such circular business models. They may have to change certain business processes, reformulate supply chains, and also redefine their customer relationships, to foster compliance with their modus operandi. These dynamic aspects can be time-consuming, costly, and resource intensive (Eisenreich et al. 2021). For instance, the customers who are accustomed to owning tangible assets may resist shifting to a product-service system model. Their reluctance to accept the service providers’ revised terms and conditions can hinder the adoption of circular economy practices. The former may struggle to convince their consumers to change their status quo, by accessing products as a service, rather than owning them (Sgambaro et al. 2024). In addition, the practitioners adopting products-as-a-service systems may find it difficult to quantify their performance outcomes related to resource savings and customer satisfaction levels and to evaluate the success of their product-service models, accurately, due to a lack of established metrics.
In a similar vein, the customers of sharing economies and leasing systems ought to trust the quality standards and safety features of the products and services they use (Sergianni et al. 2024). Any negative incidents reported through previous consumers’ testimonials and reviews can undermine the prospective customers’ confidence in the service provider or in the manufacturer who produced the product in the first place. Notwithstanding, several sharing economy models rely on community participation and localized networks, which can pose possible challenges for scalability. As businesses seek to expand their operations, it may prove hard for them to consistently maintain the same level of trust and quality in their service delivery. Moreover, many commentators argue that the rapid growth of sharing economies often outpaces existing regulatory frameworks. The lack of regulations, in certain jurisdictions, in this regard, can create uncertainties and gray areas for businesses as well as for their consumers.
Featuring excerpts from one of my latest article focused on the intersection of ESG performance and the promotion of the sustainable tourism agenda – published through Business Strategy and the Environment:
Suggested citation: Camilleri, M.A. (2025). Environmental, social and governance (ESG) factors for sustainable tourism development: The way forward toward destination resilience and growth, Business Strategy and the Environment, https://onlinelibrary.wiley.com/journal/10.1002/bse.70366
1 Introduction
Sustainable tourism is based on the principles of sustainable development (Fauzi 2025). It covers the complete tourism experience, including concerns related to economic, social and environmental issues (Bang-Ning et al. 2025; Wang and Zhang 2025). Its long-term dual objectives are to improve the tourists’ experiences of destinations they visit and to address the needs of host communities (Kim et al. 2024). Arguably, all forms of tourism have the potential to become sustainable if they are appropriately planned, led, organised and managed (Camilleri 2018). Destination marketers and tourism practitioners who pursue responsible tourism approaches ought to devote their attention to enhancing environmental protection within their territories, to mitigating the negative externalities of the tourism industry on the environment and society, to promoting fair and inclusive societies to enhance the quality of life of local residents, to facilitating exposure to diverse cultures, while fostering a resilient and dynamic economy that generates jobs and equitable growth for all (Rasoolimanesh et al. 2023; Scheyvens and Cheer 2022).
Conversely, irresponsible tourism practices can lead to the degradation of natural habitats, greenhouse gas emissions and the loss of biodiversity through air and water pollution from unsustainable transportation options, overconsumption of resources, waste generation and excessive construction (Banga et al. 2022; H. Wu et al. 2024). Indeed, any nation’s overdependence on tourism may give rise to economic difficulties during economic crises, such as increased cost of living for residents, seasonal income and precarious employment conditions, leakage of revenues when profits go to foreign-owned businesses and displacement of traditional industries like fishing and agriculture, among other contingent issues (Mtapuri et al. 2022; Mtapuri et al. 2024).
In addition, tourism may trigger social and cultural externalities like overcrowding and an increased strain on public services, occupational hazards for tourism employees and inequalities due to uneven distribution of benefits, displacement of local communities to give way to tourism infrastructures, the loss of authenticity in local traditions, an erosion of local identities and traditional lifestyles under external influence, as well as increased crime rates or illicit activities (Ramkissoon 2023).
In light of these challenges, this research seeks to provide a better understanding of how environmental, social and governance (ESG) dimensions can be embedded within sustainable tourism, to strengthen long-term destination resilience and economic growth. Debatably, although the use of the ESG dimensions is gaining traction in various corporate suites, their application in tourism and hospitality industry contexts is still limited. Notwithstanding, ESG research is still suffering from inconsistent conceptualisations, measurements and reporting systems (Legendre et al. 2024).
To address this gap, this contribution outlines five interrelated objectives: (1) It relies on a systematic review methodology to investigate the intersection of ESG principles and sustainable tourism; (2) It synthesises the findings and maps thematic connections related to environmental stewardship, social equity and governance structures in tourism destinations; (3) It evaluates ESG-based strategies that address carrying capacity limitations, overtourism, climate vulnerabilities, sociocultural tensions and institutional accountabilities; (4) It advances theoretical insights; and (5) It develops a comprehensive conceptual framework, to guide policymakers, practitioners and stakeholders in embedding ESG considerations into tourism planning and development, thereby promoting environmental sustainability, socioeconomic resilience and corporate governance.
Guided by these objectives, this timely research addresses four central research questions. Firstly, it asks: [RQ1] How have high-impact scholarly works conceptualised and operationalised ESG dimensions in order to promote sustainable travel destinations? Secondly, it seeks to answer this question: [RQ2] What empirical evidence exists on the effectiveness of ESG-aligned strategies in enhancing destination resilience and fostering long-term economic growth? The third question interrogates: [RQ3] What academic implications arise from this contribution, and how might its insights shape the future research agenda? Finally, the study seeks to address this question: [RQ4] How and in what ways are the ESG pillars interacting within sustainable tourism policy and practices? This research question recognises that the ESG dimensions may or may not always align harmoniously with the sustainable tourism agenda.
Although the sustainable tourism literature has often been linked to the United Nations Sustainable Development Goals (SDGs) and to broader corporate social responsibility (CSR) frameworks, the explicit integration of ESG principles into this field is still underdeveloped (Back 2024; Legendre et al. 2024; Lin et al. 2024; Shin et al. 2025). Much of the existing literature examines the environmental, social and governance (E, S and G) dimensions in isolation (Moss et al. 2024), with scholars often addressing, for example, environmental sustainability through climate adaptation strategies or governance via destination management systems, without adequately considering their interdependence or combined impact on tourism outcomes (Comite et al. 2025; Kim et al. 2024). This pattern was clearly evidenced in the findings of this research.
This article synthesises the findings of recent high-impact publications focused on sustainable tourism through the ESG performance lens, in order to advance a holistic conceptual model that bridges academic scholarship and policy application. In sum, this proposed theoretical framework clarifies how environmental stewardship, social inclusivity and governance accountability are shaping sustainable tourism trajectories. In conclusion, it puts forward original theoretical as well as the managerial implications. Theoretically, it enriches the sustainable tourism literature with an ESG-integrated analytical framework grounded in systematic evidence. Practically, it offers an actionable, governance-oriented blueprint that aligns environmental, social and economic objectives for responsible tourism planning and development. Hence, it provides a tangible roadmap that embeds ESG dimensions and their related criteria into sustainable tourism strategies for destination resilience and long-term competitiveness.
2 Background
The evolution of sustainable and responsible tourism paradigms can be traced back to the environmental consciousness that characterised the 1960s and 1970s. At the time, several governments were concerned over the ecological and cultural consequences of mass tourism. Early initiatives, such as the European Travel Commission’s 1973 campaign for environmentally sustainable tourism, sought to mitigate the negative externalities of rapid sector growth. Subsequently, South Africa’s 1996 national tourism policy introduced the concept of responsible tourism, that essentially emphasised community well-being as an integral component of destination management. The United Nations World Tourism Organization (UNWTO) has since positioned sustainable tourism as a catalyst for global development.
Eventually, the declaration of 2017 as the International Year of Sustainable Tourism for Development has underscored its potential to contribute directly to the United Nations SDGs. Specific targets like SDG 8 (decent work and economic growth), SDG 12 (responsible consumption and production), SDG 14 (life below water) and SDG 15 (life on land) highlight the sector’s capacity to create jobs, preserve ecosystems, safeguard cultural heritage and benefit vulnerable economies (Mahajan et al. 2024), particularly in small island states and least developed countries (Grilli et al. 2021). However, an ongoing achievement of these objectives necessitates balancing environmental, social and economic interests, a process that is often complicated by the diverse, and at times conflicting, priorities of a wide array of stakeholders (Civera et al. 2025).
Governments are important actors in this process. They can influence sustainable tourism outcomes through regulation, education, destination marketing and public–private partnerships (Dossou et al. 2023; Mdoda et al. 2024). Generally, their underlying policy rationale is to ensure that tourism development supports long-term economic growth while protecting cultural and natural assets, in order to improve community well-being (Andrade-Suárez and Caamaño-Franco 2020; Breiby et al. 2020). Yet this ambition is often undermined by market pressures, limited institutional capacities and the difficulty of translating high-level sustainability commitments into enforceable measures at the local levels.
In this light, the ESG framework a concept that was popularised by a United Nations Global Compact (2004) report, entitled, “Who Cares Wins”, offers a coherent approach for the integration of environmental stewardship, social equity and institutional accountability for the advancement of responsible tourism planning and development. Hence, in this context, practical tools are required in order to translate inconsistent guiding principles into actionable destination management strategies. For instance, the carrying capacity acts as a practical control mechanism within such a theoretical framework (Mtapuri et al. 2022; O’Reilly 1986). It ensures that tourism figures remain compatible with the preservation of natural, cultural and heritage assets. For the time being, there are challenges as well as opportunities for governments to translate the holistic vision of sustainable tourism policies into robust governance systems that maintain economic vitality and the integrity of their destinations.
4 Results
The thematic analysis indicates that the sustainable tourism concept is interconnected with each of the ESG’s dimensions. The findings suggest that sustainable tourism integrates environmental stewardship, social responsibility and sound governance to advance ecological preservation, community well-being and organisational accountability. Hence, it supports long-term destination resilience. The bibliographic results report that each of the ESG components is not only essential for sustainable tourism but also interdependent pillars that enable the sector to thrive in a responsible manner. Therefore, it is imperative for governments to safeguard natural and cultural heritage, empower local communities and foster transparent and effective governance, to ensure the sustainable development of destinations as well as their economic growth (Chong 2020; Grilli et al. 2021; Mamirkulova et al. 2020). The ESG framework, along with its criteria, serves as an important lens through which stakeholders can shape and evaluate sustainable tourism policies and practices (Işık, Islam, et al. 2025). Table 1 features the most conspicuous themes that emerged from this study. Additionally, it presents definitions for each theme along with illustrative research questions examined by the academic contributions identified in this systematic review.
4.1 The Environmental Dimension of Sustainable Tourism
The tourism industry is dependent on natural ecosystems. Therefore, it is in the tourism stakeholders’ interest to protect the environment and to minimise their externalities (J. S. Wu et al. 2021). There is scope for them to promote the conservation of land and water resources (Sørensen and Grindsted 2021). Water scarcity is a pressing global concern that is amplified in many tourist hotspots (WTTC 2023). However, tourism development and its related infrastructural expansion ought to respect ecological thresholds and preserve green spaces, particularly in urban areas. Hotels, resorts and attractions could implement water-saving technologies such as rainwater harvesting, low-flow fixtures and wastewater recycling (Foroughi et al. 2022). These sustainable measures reduce stress on local water supplies and help preserve aquatic ecosystems. In addition, tourism entities can avail themselves of renewable energy sources like solar panels, wind turbines, et cetera, and may adopt energy-efficient appliances and lighting solutions (Abdou et al. 2020; Zhan et al. 2021).
The rapid growth of tourism has historically been linked to environmental degradation through waste accumulation and pollution (Bekun et al. 2022). Circular economy strategies including improved waste management and pollution control through responsible waste disposal as well as reducing, reusing and recycling certain resources, can help decrease the industry’s externalities, but also create healthier spaces for tourists and staff (Camilleri 2025; Dey et al. 2025; Jain et al. 2024).
Tourism significantly contributes to the generation of greenhouse gas emissions through transportation and accommodation (Kim et al. 2024). Addressing climate change within sustainable tourism is critical to reducing the sector’s ecological footprint and enhancing destination resilience to climate impacts (Comite et al. 2025; Scott 2021). Many tourism businesses invest in carbon offset programs including reforestation, renewable energy projects and community-based conservation as mechanisms to offset their emissions (Banga et al. 2022). Eco-certifications such as Global Sustainable Tourism Council (GSTC), Green Globe, EarthCheck, GreenKey and LEED, among others, encourage the adoption of low-carbon practices. They enable practitioners and consumers to make environmentally conscious choices (Dube and Nhamo 2020; Gössling and Schweiggart 2022). Moreover, green transportation policies can encourage public transit, cycling, walking and the adoption of electric and hybrid vehicles for tourism-related travel, thereby reducing carbon footprints (Kim et al. 2024).
Ecologically sensitive zones such as national parks and marine reserves, which are home to wildlife, fragile species and habitats are some of the most visited places by tourists (Partelow and Nelson 2020; Tranter et al. 2022). Hence, they should be protected from overtourism by implementing visitor limits, buffer zones and conservation fees to reduce human impact (Leka et al. 2022). Restoration projects like reforestation, coral reef rehabilitation and wetland conservation are good examples of proactive environmental stewardship linked to tourism (Herrera-Franco et al. 2020; Muhammad et al. 2021). Environmental sustainability also depends on shaping tourist behaviours and fostering responsible activities like environmental awareness campaigns, community involvement in conservation efforts as well as engagement in low-impact alternatives like birdwatching, hiking and sustainable diving, among other stewardship practices (Khuadthong et al. 2025; J. S. Wu et al. 2021).
4.2 The Social Dimension of Sustainable Tourism
Sustainable tourism outcomes extend beyond environmental stewardship principles. Its social dimension encompasses criteria related to the preservation of cultural heritage; community engagement and empowerment; social equity, inclusion and cohesion; as well as responsible tourist behaviours, among other aspects (Bellato et al. 2023; Bianchi and de Man 2021; Joo et al. 2020a; Xu et al. 2020; Yang and Wong 2020; Rasoolimanesh et al. 2023). Sustainable tourism practices are clearly evidenced through improved relationships between tourists and local host communities, resulting in tangible benefits to both parties (Ramkissoon 2023).
The tourism industry can be considered a catalyst for cultural appreciation as well as a threat to cultural authenticity (Bai et al. 2024; H. Wu et al. 2024). Therefore, host destinations need to safeguard their cultural heritage, historical landmarks and monuments. Regulations and visitor management policies ought to be in place to limit wear and degradation of archaeological and religious sites, as well as historically important buildings and architectures (Mamirkulova et al. 2020). The social dimension of sustainable tourism entails that destination marketers preserve their cultural heritage and authenticity. They may do so by showcasing indigenous tastes and aromas of the region, including local foods and wines, and by promoting traditional music, dance, arts, crafts, et cetera, to appeal to international visitors (Andrade-Suárez and Caamaño-Franco 2020). This helps them keep their cultural legacy and maintain a competitive edge (Bellato et al. 2023). As a result, incoming tourists would be in a better position to appreciate local customs and folklore. Notwithstanding, their behaviours can play a crucial role in shaping social dynamics within destinations, as their activities might support community well-being and promote equitable access to tourism benefits (Mamirkulova et al. 2020).
However, policymakers are expected to manage visitor flows within a destination’s carrying capacity to prevent overcrowding, and to avoid social tensions, while fostering inclusivity, mutual respect and positive interactions between visitors and host communities (Back 2024; Koens et al. 2021). Perhaps, destination management organisations should educate visitors about cultural sensitivity issues to demonstrate their respect to host communities (Foroughi et al. 2022; Joo et al. 2020b; Mdoda et al. 2024). For example, they may raise awareness of appropriate behaviours in specific contexts, including dress codes and etiquette to mitigate cultural clashes, discourage exploitative tourism practices like invasive photography in certain settings and prevent unethical animal encounters, in order to foster mutual respect, enhance positive exchanges and safeguard community values (Ghaderi et al. 2024).
The sustainable tourism concept encourages participatory tourism planning. It prioritises the empowerment of indigenous communities in tourism decision-making and policy formulation (Ramkissoon 2023). The involvement of local residents may require capacity building to equip them with relevant skills to participate in the tourism sector, and to foster their economic advancement (Mamirkulova et al. 2020). The proponents of sustainable tourism frequently refer to the provision of fair employment opportunities, including for native populations, in terms of equitable wages and salaries, as well as decent working conditions, in order to enhance community livelihoods and social cohesion (Mtapuri, Camilleri, et al. 2022). Very often, they report that destinations would benefit from sustainable tourism practices that build social capital and reduce economic leakage, by incentivising local entrepreneurs and community-based tourism initiatives to ensure that financial returns remain within the community (Chong 2020; Partelow and Nelson 2020).
The systematic review postulates that the sustainable tourism concept is meant to promote social justice and reduce inequalities (Bianchi and de Man 2021). The extant research confirms that it fosters social inclusivity across various demographic groups in society by supporting gender equality, thereby enriching the sector’s diversity (Bellato et al. 2023; A. Khan et al. 2020). The industry’s labour market may include individuals hailing from different backgrounds in society, including young adults, women, senior citizens, immigrants and disabled people (Bianchi and de Man 2021; Camilleri et al. 2024). Tourism businesses are encouraged to develop infrastructures and services that accommodate people with accessibility requirements in order to broaden their destinations’ reach and social value (Sisto et al. 2022).
4.3 The Governance Dimension in Sustainable Tourism
The integration of environmental and social dimensions of sustainable tourism ultimately depends on transparent, accountable and participatory governance mechanisms (Joo et al. 2020b; Putzer and Posza 2024). Effective governance provides the institutional framework through which environmental stewardship and social responsibility are translated into actionable policies, coordinated initiatives and measurable outcomes (Back 2024; Ivars-Baidal et al. 2023).
Governments are entrusted to set the foundation for sustainable tourism through national and local tourism policies that clearly define sustainability goals, action plans and regulatory measures (Gössling and Schweiggart 2022). Such policies may be related to environmental and/or social regulations. They may enforce environmental impact assessments (EIAs), zoning laws and they could be meant to protect cultural heritage (Farsari 2023). Moreover, they may be intended to encourage or incentivise environmental sustainability practices (e.g., through eco-label or certification schemes) (Bekun et al. 2022). Alternatively, they may be focused on the destinations’ carrying capacity limits and/or on their overtourism aspects, if they specify visitor limits, and/or refer to taxes, levies or fees imposed on visitors or tourists (Leka et al. 2022).
Sustainable tourism governance depends on multisector cooperation (Farsari 2023) that may usually involve government departments and agencies, the private sector that may comprise accommodation service providers, airlines, tour operators, travel agencies as well as local communities, NGOs and international organisations, among others. Policymakers need to balance diverse stakeholders’ interests and to instil their shared responsibilities (Siakwah et al. 2020). Good governance can ultimately ensure that public–private partnerships would translate to long-term, sustainable tourism strategies related to responsible planning and development that consider specific socioenvironmental aspects of destinations: green building standards and the use of renewable energy, and/or emergency and crisis management issues (Scheyvens and Cheer 2022).
Policymakers are expected to conduct regular assessments and evaluations of tourism practitioners’ environmental, social and economic outcomes operating in their jurisdictions. They need to scrutinise corporate ESG disclosures, particularly in certain domains (e.g., in European contexts, where they ratified the corporate sustainability reporting directive) (Camilleri 2025). Governments should monitor business practices to safeguard their employees’ well-being, environmental sustainability and the communities’ interests (Putzer and Posza 2024). They may avail themselves of sustainability indicators and benchmarking tools such as GSTC’s criteria that are used to measure progress in sustainable tourism, in terms of sustainable management (planning, monitoring, governance); socioeconomic benefits to the local community, cultural heritage preservation and environmental protection (Wang and Zhang 2025). Such responsible and ethical practices increase trust and lead to continuous improvements in the tourism industry.
Discussion
The holistic integration of environmental, social and governance dimensions in sustainable tourism collectively contributes to enhance destination resilience and sustainable economic growth. The conservation of natural attractions such as beaches, forests and coral reefs will enable destinations to remain competitive. Therefore, there is scope in implementing climate-friendly measures, including reforestation and sustainable water management, among others, to reduce vulnerability to floods and storms. At the same time, they may curb ocean-level increases. Pollution prevention, waste minimization and circular economy strategies can help destinations maintain environmental quality, that is crucial for their ongoing tourism appeal. Notwithstanding, eco-certifications of responsible destinations can attract environmentally conscious travelers, who may be willing to pay more to visit sustainable tourism destinations.
The effectiveness of eco-certifications is amplified when combined with socially responsible practices. The integration of community empowerment, cultural heritage preservation, and social inclusiveness into tourism planning and development can contribute to increasing the sustainability of a destination. Hence, the tourism industry could add value to the environment as well as to local communities. By aligning sustainable development with local priorities and by promoting responsible tourism practices, destinations can provide authentic cultural and heritage experiences, thereby enhancing their visitor satisfaction and revisit intentions, in the future. In turn, this reinforces both market differentiation and long-term social resilience. Furthermore, as entrepreneurship flourishes, the local communities would benefit from circulating incomes and reduced economic leakages. Such outcomes are conducive to tourism growth.
However, policymakers must implement effective tourism governance to ensure that these economic gains are sustainable. Transparent governance fosters trust among stakeholders and facilitate sustainable growth and competitiveness. By implementing strategic planning and regulations, local authorities can ensure that tourism development| does not overwhelm infrastructure or degrade natural and cultural assets. This creates a balanced environment where entrepreneurship and community benefits coexist with long-term destination resilience. Therefore, sound governance prevents over-tourism and unmanaged expansion, whilst protecting the destinations’ assets. Robust tourism governance frameworks foster stable policy environments, attract further investments and enable long-term planning. Additionally, strong crisis management capabilities can equip destinations to handle unforeseen circumstances including pandemics, natural disasters and economic shocks.
The above analysis underlines that environmental, social and governance dimensions are deeply interlinked to one another and mutually-reinforcing within sustainable tourism. An integrative ESG approach conceptualizes sustainable tourism as a synergistic framework that reconciles ecological integrity, social equity, and institutional effectiveness, as illustrated in Figure 1.
Theoretical implications
This study adds value to the growing body of literature focused on sustainable tourism governance (Gössling & Schweiggart, 2022;Işık et al., 2025; Rasoolimanesh et al., 2023). It clearly identifies key theoretical underpinnings of articles focused on the intersection of ESG dimensions and sustainable tourism practices. The bibliographic findings suggest that the stakeholder theory (Bellato et al., 2023; Ivars-Baidal et al., 2023; Matsali et al., 2025; Mdoda et al., 2024) and the institutional theory (Bekun et al., 2022; Dossou et al., 2023; Hall et al., 2020; Saarinen, 2021; Zhan et al., 2021) shed light on the role of government policies, corporate responsibility and community engagement in shaping the sustainable tourism agenda and different settings (Lin et al., 2024; Zhang et al., 2025). Interestingly, the Social Identity Theory clarifies how various stakeholder groups, including residents, tourists and industry practitioners, are aligning their behaviors with shared norms and identities that promote corporate ESG values (Yang & Wong, 2020). Drawing on Cognitive Appraisal Theory, it indicates that stakeholders’ evaluation of ESG-related risks and opportunities influences their emotional responses and subsequent engagement in sustainability initiatives (Foroughi et al., 2022). The Theory of Empowerment further explains how participatory governance and transparent decision-making can enhance community agency, fostering stronger local support for ESG-driven tourism strategies (Joo et al., 2020a).
In line with the Theory of Planned Behavior and the Attitude–Behavior–Context (ABC) Theory, the findings highlight that pro-sustainability intentions are by attitudes toward ESG as well as by perceived behavioral control and contextual enablers such as policy frameworks and market incentives (Joo et al., 2020b; Khuadthong et al., 2025; Wu et al., 2021). Moreover, the Value–Belief–Norm Theory demonstrates how environmental values and moral obligations underpin behavioral commitments to ESG-aligned tourism (Kim et al., 2024).
From a governance perspective, the Evolutionary Governance Theory clarifies how institutional arrangements, stakeholder relationships and regulatory norms adapt over time to embed ESG principles in tourism planning (Partelow & Nelson, 2020). The review suggests that tourism stakeholders’ decision-making including during uncertain situations, can be enriched through Decision Theory and by referring to the Interval-Valued Fermatean Fuzzy Set approach (Rani et al., 2022). These theories enable robust, data-informed prioritization of ESG objectives.
Furthermore, the findings underscore the recursive relationship between the human agency and the structural constraints. The results suggest that stakeholder actions can influence ESG governance systems. This argumentation is congruent with the Structuration Theory (Saarinen, 2021). Meanwhile, the Resource-Based View (Wang & Zhang, 2025; Zhu et al., 2021) and Dynamic Capabilities Theory (Wang & Zhang, 2025) frame ESG adoption as a strategic asset, where unique sustainability capabilities can enhance competitive advantage and long-term destination resilience.
Managerial implications
This research yields clear implications for policymakers, industry practitioners and local communities of tourist destinations. It postulates that the ESG dimensions can provide these stakeholders with a strategic framework to balance growth with long-term resilience. It confirms that ESG policies necessitate a comprehensive approach, that combines environmental conservation, social inclusion, and responsible governance considerations, rather than addressing them individually. Arguably, there may be variations in the importance, focus and implementation of ESG dimensions in tourism, in different contexts, due to the host countries’ economic capacities regulatory frameworks, social priorities and/or environmental challenges. As a result, the effects or outcomes of ESG initiatives are not uniform across destinations (Lin et al., 2024).
In addition, the size of the businesses can also influence their commitment to account and disclose ESG-related aspects of their performance. Large multinational travel and hospitality firms could benefit from economies of scale, in terms of greater financial, human, and technological resources, resulting in their ESG alignment and compliance with societal norms and regulatory frameworks. They can afford dedicated sustainability teams, advanced data management tools, and external consultants to ensure accurate measurement, benchmarking and disclosure of ESG performance. In stark contrast, the smaller firms may face resource constraints, limited expertise, and higher relative costs for data collection and reporting. Such non-commercial activities can hinder their ability to systematically track, measure and communicate ESG performance, placing them at a comparative disadvantage, relative to their larger counterparts.
From an environmental perspective, policy makers should operationalize carrying capacity thresholds and implement adaptive management systems to safeguard ecosystems, optimize resource utilization, and enhance climate resilience. Continuous monitoring and evaluation of environmental impacts are essential to ensure that tourism activities remain within sustainable limits. Proactive interventions including the promotion of low-carbon transportation, the adoption of renewable energy, efficient resource management, and waste reduction are critical for aligning tourism development with ESG objectives. Such strategies preserve biodiversity and can contribute to the long-term sustainability of destinations.
The social dimension emphasizes the equitable distribution of tourism benefits and the preservation of cultural integrity. Overtourism threatens community well-being through inflated living costs, cultural commodification and resident–visitor tensions. Hence, managers should foster participatory governance structures that empower local communities, entrepreneurs and cultural custodians in decision-making processes. Technological innovations including artificial intelligence (AI) solutions that monitor visitor flows can further support socially responsible destination management. At the same time, stakeholder engagement ensures that tourism operations retain their legitimacy in society.
Robust governance mechanisms underpin these strategies. Practitioners can align policies with international sustainability standards in order to facilitate transparent accountability. The implementation of ESG performance indicators, enforceable visitor limits and adaptive regulatory measures, such as dynamic pricing or quotas enable evidence-based decision-making and continuous improvements in responsible destinations. The strengthening of institutional capacities and local skills ensures that governance frameworks are effective and sustainable over time.
Financial innovation is essential for sustainable tourism development. Policy makers ought to invest in green technologies and infrastructures to protect the natural environment from externalities. They can provide incentives and funds to support practitioners in their transition to long-term sustainability. By embedding ESG principles, destinations are in a better position to enhance their resilience to environmental and social shocks, strengthen their reputation and image, whilst maintaining their competitiveness in the global tourism market.
Policymakers are encouraged to increase their enforcement of regulations to trigger responsible behaviors. At the same time, they need to nurture relationships with stakeholders. The hoteliers should embed social innovations and environmentally sustainable practices into core strategies and operations. As for local communities, it is in their interest to actively participate in tourism planning and development, to ensure they preserve their cultural heritage and share tourism benefits in a fair manner. Collectively, this contribution’s integrated ESG approach positions destinations for sustained economic growth while safeguarding environmental and social well-being.
Conclusion
This article reinforces the significance of integrating ESG principles into sustainable tourism strategies. By addressing environmental concerns, fostering social inclusivity, improving governance frameworks, and ensuring economic viability, stakeholders can contribute to a more resilient and responsible tourism sector. This research demonstrates that sustainable tourism is most effectively achieved through the integration of environmental, social, and governance (ESG) dimensions, which together foster long-term destination resilience and economic growth. Environmentally, sustainable tourism requires the preservation of natural ecosystems, efficient resource use, and proactive measures to reduce pollution and greenhouse gas emissions. Practices such as water-saving technologies, renewable energy adoption, waste reduction, and circular economy strategies not only mitigate ecological impacts but also enhance the attractiveness and competitiveness of destinations.
From a social perspective, sustainable tourism supports community empowerment, cultural preservation, inclusivity, and social equity. By engaging local residents in planning and decision-making, promoting equitable employment, and safeguarding cultural heritage, destinations can foster positive resident–visitor interactions and enhance the overall visitor experience. Responsible tourist behavior, participatory governance, and cultural sensitivity further reinforce social cohesion while ensuring that tourism benefits are broadly shared within host communities.
Effective governance underpins both environmental and social outcomes by providing transparent, accountable, and coordinated frameworks for sustainable tourism. Policymakers and destination managers play a critical role in enforcing regulations, monitoring ESG performance, and balancing stakeholder interests. Multi-sector collaboration, the application of sustainability indicators, and adaptive management strategies enable destinations to anticipate and respond to environmental, social, and economic shocks.
Collectively, the ESG approach positions sustainable tourism as a synergistic model that aligns ecological integrity, social responsibility, and institutional effectiveness. By embedding ESG principles into core strategies, destinations can deliver unique, high-quality experiences, strengthen community livelihoods, and maintain global competitiveness. This integrative framework demonstrates that environmental stewardship, social equity, and sound governance are mutually reinforcing, offering a pathway for destinations to achieve enduring sustainability, resilient growth, and enhanced market differentiation.
Very pleased to share this timely article that examines the antecedents of the users’ trust in Generative AI’s recommendations, related to travel and tourism planning.
I would like to thank my colleagues (and co-authors), namely, Hari Babu Singu, Debarun Chakraborty, Ciro Troise and Stefano Bresciani, for involving me in this meaningful research collaboration. It’s been a real pleasure working with you on this topic!
•The study focused on the enablers and the inhibitors of generative AI usage
•It adopted 2 experimental studies with a 2 × 2 between-subjects factorial design
•The impact of the cognitive load produced mixed results
•Personalized recommendations explained each responsible AI system construct
•Perceived controllability was a significant moderator
Abstract
Generative AI models are increasingly adopted in tourism marketing content based on text, image, video, and code, which generates new content as per the needs of users. The potential uses of generative AI are promising; nonetheless, it also raises ethical concerns that affect various stakeholders. Therefore, this research, which comprises two experimental studies, aims to investigate the enablers and the inhibitors of generative AI usage. Studies 1 (n = 403 participants) and 2 (n = 379 participants) applied a 2 × 2 between-subjects factorial design in which cognitive load, personalized recommendations, and perceived controllability were independently manipulated. The initial study examined the probability of reducing the cognitive load (reduction/increase) due to the manual search for tourism information. The second study considers the probability of receiving personalized recommendations using generative AI features on tourism websites. Perceived controllability was treated as a moderator in each study. The impact of the cognitive load produced mixed results (i.e., predicting perceived fairness and environmental well-being), with no responsible AI system constructs explaining trust within Study 1. In study 2, personalized recommendations explained each responsible AI system construct, though only perceived fairness and environmental well-being significantly explained trust in generative AI. Perceived controllability was a significant moderator in all relationships within study 2. Hence, to design and execute generative AI systems in the tourism domain, professionals should incorporate ethical concerns and user-empowerment strategies to build trust, thereby supporting the responsible and ethical use of AI that aligns with users and society. From a practical standpoint, the research provides recommendations on increasing user trust through the incorporation of controllability and transparency features in AI-powered platforms within tourism. From a theoretical perspective, it enriches the Technology Threat Avoidance Theory by incorporating ethical design considerations as fundamental factors influencing threat appraisal and trust.
Introduction
Information and communication technologies have been playing a key role in enhancing the tourism experience (Asif and Fazel, 2024; Salamzadeh et al., 2022). The tourism industry has evolved as a content-centric industry (Chuang, 2023). It means the growth of the tourism sector is attributed to the creation, distribution, and strategic use of information. The shift from the traditional model of demand–driven to the content-centric model represents a transformation in user behaviour (Yamagishi et al., 2023; Hosseini et al., 2024). Modern travellers are increasingly dependent on user-generated content to decide on their choices and travel planning (Yamagishi et al., 2023; Rahaman et al., 2024). The content-focused marketing approach in tourism emphasizes the role of digital tools and storytelling to assist in creating a holistic experience (Xiao et al., 2022; Jiang and Phoong, 2023). From planning a trip to sharing cherished memories, content helps add value to the travellers and tourism businesses (Su et al., 2023). For example, MakeMyTrip (MMT) integrated generative AI trip planning assistant which facilitates conversational bookings assisting the users with destination exploration, in-trip needs, personalized travel recommendations, summaries of hotel reviews based on user content and voice navigation support positioning the MMT’s platform more inclusive to the users. The content marketing landscape is changing due to the introduction of generative AI models that help generate text, images, videos, and interesting code for users (Wach et al., 2023; Salamzadeh et al., 2025). These models assist in expressing the language, creativity, and aesthetics as humans do and enhance user experience in various industries, including travel and tourism (Binh Nguyen et al., 2023; Chan and Choi, 2025; Tussyadiah, 2014).
Gen AI enhances natural flow of interactions by offering personalized experiences that align with consumer profiles and preferences (Blanco-Moreno et al., 2024). Gen AI is gaining significant momentum for its transformative impact within the tourism sector, revolutionizing marketing, operations, design, and destination management (Duong et al., 2024; Rayat et al., 2025). Accordingly, empirical studies suggest that Generative AI has the potential to transform tourists’ decision-making process at every stage of their journey, demonstrating a significant disruption to conventional tourism models (Florido-Benítez, 2024). Nonetheless, concerns have been raised about the potential implications of generative AI models, and their generated content might possess inaccurate or deceptive information that could adversely impact consumer decision-making (Kim et al., 2025a, Kim et al., 2025b). In its report titled “Navigating the future: How Generative Artificial Intelligence (AI) is Transforming the Travel Industry”, Amadeus highlighted key concerns and challenges in implementation Gen AI such as data security concerns (35 %), lack of expertise and training in Gen AI (34 %), data quality and inadequate infrastructure (33 %), ROI concerns and lack of clear use cases (30 %) and difficulty in connecting with partners or vendors (29 %). Therefore, the present study argues that with the intuitive design, the travel agents could tackle the lack of expertise and clear use of Gen AI. The study suggests that for travel and tourism companies to build trust in Gen AI, they must tackle the root causes of user apprehension. This means addressing what makes users fear the unknown, ensuring they understand the system’s purpose, and fixing problems with biased or poor data. Also, previous studies highlighted how the integration of Gen AI and tourism throws certain issues such as misinformation and hallucinations, data privacy and security, human disconnection, and inherent algorithmic biases (Christensen et al., 2025; Luu et al., 2025). Moreover, if Gen AI provides biased recommendations, the implications are adverse. If the users perceive that the recommendations are biased, they avoid using them, leading to high churn and abandoning platforms (Singh et al., 2023). Users’ satisfaction will decline, replaced by frustration and anger as biased output damages the promise of personalized services. This negatively impacts brand reputation and loss of significant market competitive advantage (Wu and Yang, 2023). Such scenarios will likely lead to stricter regulations, mandatory algorithmic audits, and new consumer protection laws forcing the industry to prioritize fairness as well as explainability to avoid serious consequences. Interestingly, research studies draw attention to an interesting paradox, that consumers are heavily relying on AI-generated travel itineraries, even when they are aware of Gen AI’s occasional inaccuracies (Osadchaya et al., 2024). This reliance might stem from a belief that AI’s perceived objectivity and capacity for personalized recommendations indicate a significant transformation of trust between human and non-human agents in the travel decision-making process (Kim et al., 2023a, Kim et al., 2023b). Empirical findings indicate that AI implementation in travel planning contributes to the objectivity of the results, effectively mitigates cognitive load, and supports higher levels of personalization aligned with user preferences (Kim et al., 2023a, Kim et al., 2023b). Despite the growing body of literature explaining the role of trust in Gen AI acceptance and its influence on travellers’ decision making and behavioural intentions, the potential biases in AI-generated content continue to pose challenges to users’ confidence (Kim et al., 2021a, Kim et al., 2021b). Therefore, this research aims to examine the influence of generative AI in tourism on consumers’ trust in AI technologies, particularly their balance between technological progress and ethical responsibility, concerning the future of tourism (Dogru(Dr. True et al., 2025).
Existing research has focused more on the technology of AI as a phenomenon rather than translating those theories into studies on how the ethics involved would affect perceptions and trust (Glikson and Woolley, 2020). In addition, there is still the black box phenomenon, which is the inability of the user to understand what happens in AI. It also emphasizes the need for more integrative studies between morally sound AI development, user trust, and design in tourism (Tuo et al., 2024).
Moreover, scant research has examined the factors that inhibit tourists from embracing Generative AI technologies, resulting in limited understanding of travellers’ reluctance to Generative AI adoption for travel planning (Fakfare et al., 2025). Despite a growing body of literature examining the antecedents and outcomes of Generative AI (GAI) adoption, large body of research has been based on established frameworks such as Information Systems Success (ISS) model (Nguyen and Malik, 2022), Technology Acceptance Mode; (TAM) (Chatterjee et al., 2021), and the Unified Theory of Acceptance and Use of Technology (UTAUT) (Venkatesh, 2022).
However, the extensive reliance on traditional acceptance models might face the risk of ignoring the critical socio-technical aspects, which are paramount in the context of GAI (Yu et al., 2022). While most of the studies explore the overarching effects of user acceptance and use of GenAI using TAM, UTAUT, and Delone and McLean IS success models, there has been a lack of consideration of ethical factors as well as responsible AI systems. Addressing these gaps could significantly broaden our theoretical understanding of how individuals evaluate and adopt generative AI technologies within users’ ethical behaviour and socio-technical perspective.
Therefore, this research aims to fill this gap by investigating factors that facilitate or inhibit trust in generative AI systems, considering responsible AI and Technology Threat Avoidance Theory, and advancing the following research questions:
RQ1
How does the customer experience of using generative AI in tourism reflect the impact of enablers (such as responsible AI systems) and inhibitors (such as ambiguity and anxiety) on trust in generative AI?
RQ2
Does perceived controllability moderate the enablers and inhibitors of trust in generative AI in tourism?
This research includes responsible AI principles and the technology threat avoidance theory to explicate the relationship between generative AI and trust in tourism. Seen from the conceptual lens of Ethical Behaviours, responsible AI principles are crucial for enhancing trust in Gen AI within tourism (Law et al., 2024). When users perceive Gen AI recommendations as fair, transparent, and bias-free, they are more likely to perceive the systems as trustworthy, which in turn mitigates user skepticism and promotes trust (Ali et al., 2023). Also, when Gen AI promotes sustainable and environmentally friendly practices, it demonstrates ethical responsibility and enhances trust in alignment with shared social values (Díaz-Rodríguez et al., 2023). By operationalizing responsible AI principles like transparency, fairness, and sustainability, Gen AI transforms from a black-box tool into a more trustworthy and responsible system for travel decisions (Kirilenko and Stepchenkova, 2025). From the socio-technical perspective, the Technology threat avoidance theory (TTAT) supports the logic of how perceived ambiguity and perceived anxiety act as inhibitors of trust. In tourism, users’ experience holds paramount importance (Torkamaan et al., 2024). When users encounter Gen AI content that is difficult to comprehend, recommendations are unstable or ambiguous, and users’ data is exposed to privacy concerns, these apprehensions will turn into a threat to using Gen AI (Bang-Ning et al., 2025). According to TTAT, when users perceive a greater threat, they are more inclined to engage in avoidance behaviours, which also erodes trust in the system. Hence, TTAT explains why users might hesitate or avoid using Gen AI tools, even if they offer functional benefits such as personalized recommendations and reduced cognitive load (Shang et al., 2023).
The study adopted an experimental research design that would help us to explore the independent phenomenon (use of Gen AI for content generation) and observe and explain its role to establish a cause-and-effect relationship between factors of responsible AI systems and TTAT (Leung et al., 2023). The experimental setting helps us to understand the differences empirically between human and non-human generated content from users’ travel decision-making perspective towards destinations. The study enriched the literature on both the ethical aspects and environmental aspects (perceived fairness and environmental well-being) and the perceived risks (perceived ambiguity and perceived anxiety) perspective in the tourism context. The situation of perceived controllability as a moderator is tested in the literature, offering help to managers on how to develop AI systems responsible for lowering user fear and building trust. The study also facilitated practitioners in understanding how the personalized recommendations & cognitive load facilitated by Gen AI in content generation impact the Gen AI Trust of the tourists.
Access through your organization
Check access to the full text by signing in through your organization.
Section snippets
Responsible AI systems
Responsible AI adequately incorporates ethical aspects of AI system design and implementation and ensures that the systems are transparent, fair, and responsible (Díaz-Rodríguez et al., 2023). Responsible AI includes ethical, transparent, and accountable use of artificial intelligence systems, ensuring they are fair, secure, and aligned with societal values. It is also an approach to design, develop, and deploy AI systems so that they are ethical, safe, and trustworthy. It is a system that
Cognitive load, personalized recommendations, and perceived fairness
Cognitive load is the mental effort to process and choose information (Islam et al., 2020). A cognitive load can also be high when people interact with complex systems such as AI. Thus, high cognitive load may affect the ability of users to judge whether the AI-based decisions can be considered fair, since they may not grasp enough of the workings of the system and its specific decisions (Westphal et al., 2023). On the other hand, whereas perceived fairness refers to the users’ feelings about
Research methods and analysis
The experiments adopted in this study are scenario-based. Participants’ emotions cannot be manipulated easily in an ethical manner (Anand and Gaur, 2018). Also, the scenario-based approach helps test the causal relationship between constructs used for experimentation in a given scenario. This approach also reduces the minimal interference from extraneous variables. In this method, respondents answered questions based on hypothetical scenarios developed in each scenario. Therefore, scenarios
Discussion
Study 1 shows that cognitive load is detrimental to an individual’s notion of justice or environmental wellbeing, indicating that such factors may be difficult for a user to rate properly based on expending greater cognitive effort. However, cognitive load can also limit the extent of open-mindedness and critical evaluation of AI-assisted communication (T. Li et al., 2024), which could leave people resorting to mental shortcuts or simple fairness and environmental fairness issues. Under such
Theoretical implications
Trust is an important element in the design of organizations and systems, and the current study’s theoretical implications extend the understanding of trust in generative AI systems by integrating constructs of responsible AI and Technology Threat Avoidance Theory. This research underscores the significance of moral factors in creating and using AI systems by exploring relationships between perceived justice, environmental concern, and trust. In this context, the study notes that the degree of
Practical implications
To develop and retain users’ confidence, professionals in the field should observe responsible AI principles, particularly perceived equity and ecological sustainability. It is possible for consumers to be amused by and trust that AI recommendations are perceived as fair. This involves developing algorithms that align with users’ interests while promoting green aspects in AI. It also becomes important for management to note that during AI interface design, cognitive load should be considered so
Limitations and future research
This study has certain limitations. First, the use of self-reported measures could pose certain biases, as the participants’ experiences with generative AI or social desirability could affect their judgment. The reliance on self-reported data introduces potential biases from participants’ prior engagements with generative AI, social desirability bias, or limited technological competence. Secondly, focusing on a particular context (i.e., tourism) can be seen as a limitation when it comes to
Conclusion
A thorough examination of advancing artificial intelligence in the tourism industry draws attention to the fact that there is no way of avoiding the issue of encouraging responsible AI use. Extending user satisfaction with rhetoric based on AI suggests that user perceptions are not only shaped by the quality of the recommendations but also by the ethical implications of the system and users’ affective states. A range in the effect of personalized suggestions on some parameters that influenced
📌 ICETT2025’s conference proceedings were published through the Institute of Electrical and Electronics Engineers (IEEE). This underlines the international standing and scholarly credibility of this conference.
📌 All accepted papers will be peer-reviewed, presented during the conference and published via ICETT’s 2026 Conference Proceedings. They will be indexed by EI Compendex and Scopus, among other recognised academic databases.
Conference topics include (but are not limited to):
E-learning and online learning
Game-based learning
Learning analytics and education big data
MOOCs (Massive Open Online Courses)
Mobile & ubiquitous learning
Online platforms and environments
Open educational resources
Podcasting and broadcasting
Social media for teaching and learning
Virtual reality for teaching and learning
The papers’ submission deadline is the 20th of December, 2025.
I am delighted to share this call for papers for the European Academy of Management’s (EURAM2026’s) SIG01: Business for Society (B4S).
My colleagues, Mario Tani, University of Naples Federico II, Naples, Italy; Gianpaolo Basile, Università Telematica Universitas Mercatorum, Rome, Italy; Ciro Troise, University of Turin, Turin, Italy; Maria Palazzo, Università Telematica Universitas Mercatorum, Rome, Italy; Asha Thomas, Wrocław University of Science and Technology AND I, are guest editing a track entitled: “Relationships, Values, and Community-driven (Social) Innovation in Collaborative Ecosystems” (T01-14).
We are inviting conceptual, empirical and methodological papers on the interplay between open innovation, digital platforms and the power of the crowd in navigating today’s grand challenges.
“This track explores the strategic shift from firm-centric models to dynamic, collaborative ecosystems. We examine how deep stakeholder engagement, shared values, and community-driven innovation can generate sustainable economic, social, and environmental value”.
Further details about this conference track are available here: https://lnkd.in/djN8KpDw [T01-14].
Keywords: EURAM2026; Business For Society B4S; Collaborative Ecosystems; Open Innovation Community Driven Innovation; Stakeholder Engagement; Digital; Digital Platforms; Digital Transformation; Crowdsourcing; Sustainable Development Goals (SDGs); UNSDGs; SDG9 [Industry, Innovation And Infrastructure]; SDG11 [Sustainable Cities And Communities]; SDG12 [Responsible Consumption And Production]; SDG17 [Partnerships For The Goals].
Erbatax (14) mill-membri akkademiċi ta’ l-Universita’ ta’ Malta, li jinkludu lil Daphne Attard, Fakultà tax-Xjenza; Everaldo Attard, Istitut tax-Xjenzi Rurali; Godfrey Baldacchino, Fakultà ta’ l-Arti; Jean Calleja-Agius, Fakultà tal-Mediċina u s-Servizzi Kirurġiċi; Mark Anthony Camilleri, Fakultà tal-Media u x-Xjenza ta’ l-Għarfien; Albert R. Caruana, Fakultà tal-Media u x-Xjenza ta’ l-Għarfien; Sarah Cuschieri, Fakultà tal- Mediċina u s-Servizzi Kirurġiċi; Michael Galea, Fakultà tal-Inġinerija; Ruben Gatt, Fakultà tax-Xjenza; Joseph N. Grima, Fakultà tax-Xjenza; Jackson Levi-Said, Istitut tax- Xjenzi tal-Ispazju u l-Astronomija; Peter Mayo, Fakultà tal-Edukazzjoni; Eleanor M.L. Scerri, Fakultà ta’ l-Arti; u Brendon P. Scicluna, Fakultà tax-Xjenzi tas-Saħħa (dawn l- ismijiet huma mqassmin skont l-ordni alfabetiku), ġew inklużi f’lista magħrufa bħala l- klassifika tal-aqwa 2% riċerkaturi fid-dinja, li hi ikkompilata mill-Universita’ ta’ Stanford, b’kollaborazzjoni ma’ publikatur internazzjonali ta’ kotba u rivisti akkademiċi, Elsevier. Dawn l-akkademiċi ġew rikonoxxuti għall-għadd ta’ ċitazzjonijiet li rċevew il- pubblikazzjonijiet tagħhom, matul is-sena 2024.
Barra minn hekk, disgha (9) kollegi Maltin iddistingwew ruħhom ghal publikazzjonijiet akkademiċi tul il-karriera tagħhom. Dawn ta’ l-aħħar jinkludu lil:
Professur Mark A. Camilleri (c-score 3.7352); Professur Albert R. Caruana (c-score 3.6561); Professur Godfrey Baldacchino (c-score 3.6299); Professur Sarah Cuschieri (c-score 3.5770); Professur Joseph N. Grima (c-score 3.3261); Professur Donia R. Baldacchino (c-score 3.0595); Professur Norman Poh (c-score 2.9874); Professur Michael Galea (c-score 2.7935); u Professur Antonios Liapis (c-score 2.7905).
Din l-aħbar tenfasizza l-impenn ta’ l-Università ta’ Malta sabiex tikseb eċċellenza fil- qasam tar-riċerka u l-innovazzjoni, f’dixxiplini varji, li jinkludu n-negozju u l-immaniġġjar, l-inġinerija, il-mediċina u x-xjenzi tas-saħħa, kif ukoll fix xjenzi umanistici u dawk soċjali. Il-kontributur ta’ dan l-istudju globali huwa l-Professur John P.A. Ioannidis mill-Università ta’ Stanford. L-għażla tiegħu hija “ibbażata fuq l-aqwa 100,000 xjenzati skont il-punteġġ hekk imsejjah ‘c-score’ jew fuq rank percentwali ta’ 2% jew aktar fl-oqsma rispettivi tagħhom”. L-indikaturi taċ-ċitazzjonijiet u l-metodoloġija tal-klassifiki tiegħu jinsabu f’ dan il-portal: https://elsevier.digitalcommonsdata.com/datasets/btchxktzyw/8
Ċitazzjoni suġġerita: Ioannidis, John P.A. (2025), “Updated science-wide author databases of standardized citation indicators”, Elsevier Data Repository, V8, doi: 10.17632/btchxktzyw.8
University of Malta has recently appraised its academic members of staff, who were listed among the world’s top 2% scientists, in Elsevier-Stanford University’s 2025 ranking: https://lnkd.in/dQmrPqz5
In this media release, the University of Malta has identified those who were recognized for their “career-long” (lifetime) high-impact publications, including:
Professor Camilleri, Mark A. (c-score 3.7352); Professor Caruana, Albert R. (c-score 3.6561); Professor Baldacchino, Godfrey (c-score 3.6299); Professor Cuschieri, Sarah (c-score 3.5770); Professor Grima, Joseph N. (c-score 3.3261); Professor Baldacchino, Donia R. (c-score 3.0595); Professor Poh, Norman (c-score 2.9874); Professor Galea, Michael (c-score 2.7935); and Professor Liapis, Antonios (c-score 2.7905).
The contributor of this global study is Stanford University Professor, John P.A. Ioannidis. His selection is “based on the top 100,000 scientists by c-score or a percentile rank of 2% or above in the sub-field”.
The citation indicators and the methodology of his rankings are available here: https://lnkd.in/dpxrCJtx
Suggested citation: Camilleri, M.A. (2025). Cocreating Value Through Open Circular Innovation Strategies: A Results-Driven Work Plan and Future Research Avenues, Business Strategy and the Environment, https://doi.org/10.1002/bse.4216
This research raises awareness of practitioners’ crowdsourcing initiatives and collaborative approaches, such as sharing ideas and resources with external partners, expert consultants, marketplace stakeholders (like suppliers and customers), university institutions, research centers, and even competitors, as the latter can help them develop innovation labs and to foster industrial symbiosis (Calabrese et al. 2024; Sundar et al. 2023; Triguero et al. 2022). It reported that open innovation networks would enable them to work in tandem with other entities to extend the life of products and their components. It also indicated how and where circular open innovations would facilitate the sharing of unwanted materials and resources that can be reused, repaired, restored, refurbished, or recycled through resource recovery systems and reverse logistics approaches. In addition, it postulates that circular economy practitioners could differentiate their business models by offering product-service systems, sharing economies, and/or leasing models to increase resource efficiencies and to minimize waste.
Arguably, the cocreation of open innovations can contribute to improve the financial performance of practitioners as well as of their partners who are supporting them in fostering closed-loop systems and sharing economy practices. They enable businesses and their stakeholders to minimize externalities like waste and pollution that can ultimately impact the long-term viability of our planet. Figure 1 presents a conceptual framework that clarifies how open innovation cocreation approaches can be utilized to advance circular, closed-loop models while adding value to the businesses’ financial performance.
The collaborative efforts between organizations, individuals, and various stakeholders can lead to sustainable innovations, including to the advancement of circular economy models (Jesus and Jugend 2023; Tumuyu et al. 2024). Such practices are not without their own inherent challenges and pitfalls. For example, resource sharing, the recovery of waste and by-products from other organizations, and industrial symbiosis involve close partnership agreements among firms and their collaborators, as they strive in their endeavors to optimize resource use and to minimize waste (Battistella and Pessot 2024; Eisenreich et al. 2021). While the open innovation strategies that are mentioned in this article can lead to significant efficiency gains and to waste reductions, practitioners may encounter several difficulties and hurdles, to implement the required changes (Phonthanukitithaworn et al. 2024). Different entities will have their own organizational culture, strategic goals, and modus operandi that may result in coordination challenges among stakeholders.
Organizations may become overly reliant on sharing resources or on their symbiotic relationships, leading to vulnerabilities related to stakeholder dependencies (Battistella and Pessot 2024). For instance, if one partner experiences disruptions, such as operational issues or financial difficulties, it can adversely affect the feasibility of the entire network. Notwithstanding, organizations are usually expected to share information and resources when they are involved in corporate innovation hubs and clusters. Their openness can lead to concerns about knowledge leakages and intellectual property theft, which may deter companies from fully engaging in resource-sharing initiatives, as they pursue outbound innovation approaches.
Other challenges may arise from resource recovery, reverse logistics, and product-life extension strategies (Johnstone 2024). The implementation of reverse logistics systems can be costly, especially for small and micro enterprises. The costs associated with the collection, sorting, and processing of returned products and components may outweigh the benefits, particularly if the market for recovered materials is not well established (Panza et al. 2022; Sgambaro et al. 2024). Moreover, the effectiveness of resource recovery methodologies and of product-life extension strategies would be highly dependent on the stakeholders’ willingness to return products or to participate in recycling programs. Circular economy practitioners may have to invest in promotional campaigns to educate their stakeholders about sustainable behaviors. There may be instances where existing recovery and recycling technologies are not sufficiently advanced or widely available, in certain contexts, thereby posing significant barriers to the effective implementation of open circular innovations. Notwithstanding, there may be responsible practitioners and sustainability champions that may struggle to find reliable partners with appropriate technological solutions that could help them close the loop of their circular economy.
In some scenarios, emerging circular economy enthusiasts may be eager to shift from traditional product sales models to innovative product-service systems. Yet, such budding practitioners can face operational challenges in their transitions to such circular business models. They may have to change certain business processes, reformulate supply chains, and also redefine their customer relationships, to foster compliance with their modus operandi. These dynamic aspects can be time-consuming, costly, and resource intensive (Eisenreich et al. 2021). For instance, the customers who are accustomed to owning tangible assets may resist shifting to a product-service system model. Their reluctance to accept the service providers’ revised terms and conditions can hinder the adoption of circular economy practices. The former may struggle to convince their consumers to change their status quo, by accessing products as a service, rather than owning them (Sgambaro et al. 2024). In addition, the practitioners adopting products-as-a-service systems may find it difficult to quantify their performance outcomes related to resource savings and customer satisfaction levels and to evaluate the success of their product-service models, accurately, due to a lack of established metrics.
In a similar vein, the customers of sharing economies and leasing systems ought to trust the quality standards and safety features of the products and services they use (Sergianni et al. 2024). Any negative incidents reported through previous consumers’ testimonials and reviews can undermine the prospective customers’ confidence in the service provider or in the manufacturer who produced the product in the first place. Notwithstanding, several sharing economy models rely on community participation and localized networks, which can pose possible challenges for scalability. As businesses seek to expand their operations, it may prove hard for them to consistently maintain the same level of trust and quality in their service delivery. Moreover, many commentators argue that the rapid growth of sharing economies often outpaces existing regulatory frameworks. The lack of regulations, in certain jurisdictions, in this regard, can create uncertainties and gray areas for businesses as well as for their consumers.


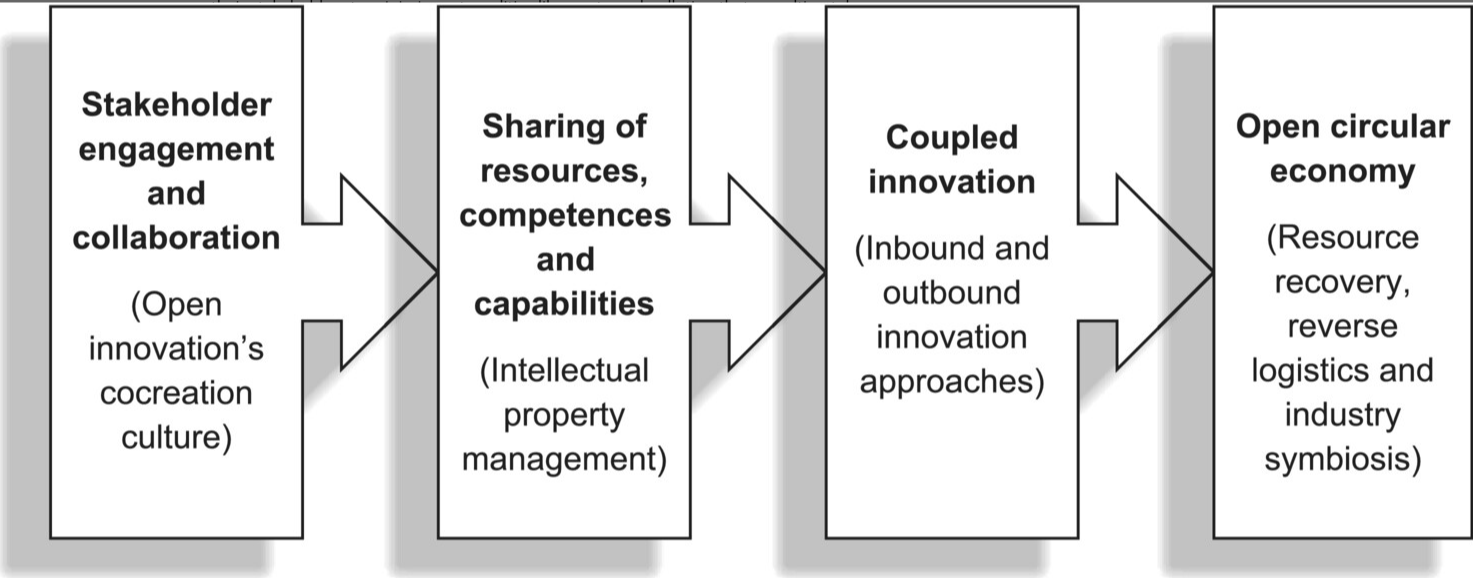


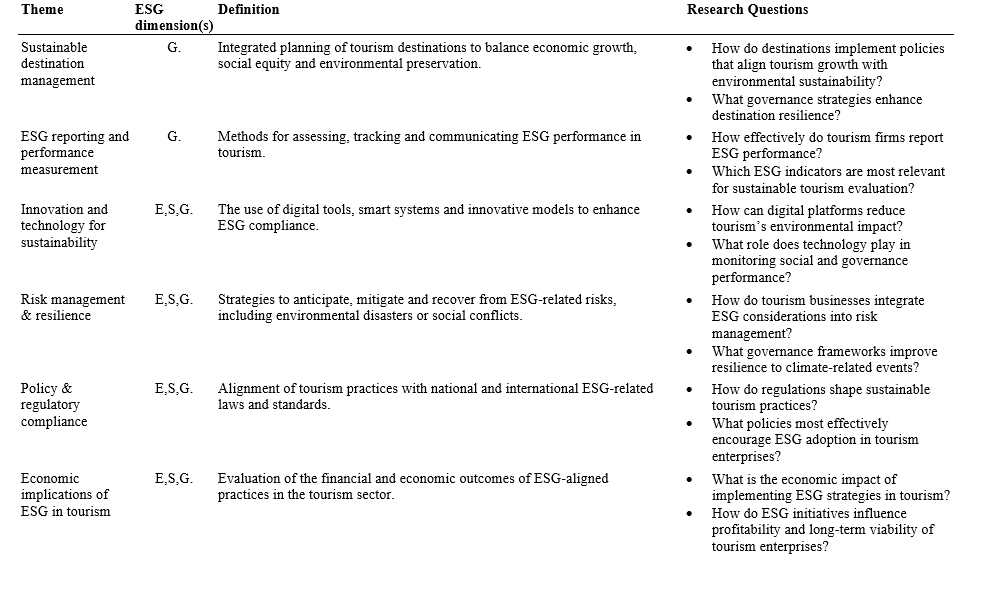
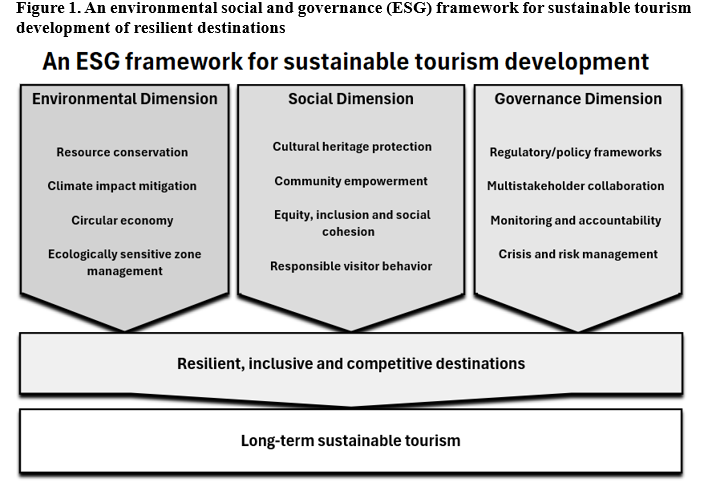






You must be logged in to post a comment.